AI/ML Projects

StyLLE: Stylized Text and Speech Generation via Latent Editing
Click to view the Research Report
Phase 1 Code: Text Stylization | Phase 2 Code: Speech Stylization
Phase 1: Improving DRESS for Large Language Models
This phase enhances the DRESS representation editing framework to enable more efficient and precise style control over LLM outputs.
- Adaptive Subspace Selection: Replaced fixed-rank heuristics with automatic style subspace rank determination using Bayesian Information Criterion (BIC), tailored per attention head.
- Localized Style Steering: Introduced a K-Nearest Neighbor (KNN) editing strategy to compute style vectors based on local activation neighborhoods for fine-grained style transfer.
- Accelerated Inference: Implemented a decoupled KV-caching mechanism to reuse key/value caches across base and stylized forward passes, achieving a 3× speed-up with negligible quality loss.
- Experiments on English (Shakespeare) and Chinese (Dream of the Red Chamber) stylized QA benchmarks confirmed improvements across Style Intensity (SI), Semantic Preservation (SP), and Fluency.
Phase 2: Extending DRESS to Speech with Spark-TTS
This phase applies the steering-vector editing framework to text-to-speech (TTS) generation using Spark-TTS, enabling attribute-based voice transformation without retraining.
- Single-DRESS SparkTTS: Applied editing on final-token activations to steer outputs from an original style (e.g., female, high-pitch) to a target style (e.g., male, low-pitch).
- Double-DRESS SparkTTS: Proposed a novel approach that separately edits global tokens (style) and semantic tokens (content), improving generation stability and intelligibility.
- Evaluated using SIM (Speaker Similarity), UTMOS (naturalness), STOI (intelligibility), and WER (accuracy). Double-DRESS outperformed all baselines across metrics while reducing generation failures (EOS miss rate).
Fourier-Based Upsampling in Image De-Raining and Segmentation
Click to view the Research Report
This project enhances the Deep Fourier Up-sampling framework to improve its performance and adaptability in image de-raining and semantic segmentation.
- Introduced stacked Fourier modules (e.g., pad_area, pad_corner) that combine different Fourier interpolation methods to balance structural fidelity and high-frequency detail preservation.
- Designed a novel Fourier Attention Module (pad_attention) that applies self-attention directly in the frequency domain, allowing the network to emphasize informative frequency components for better reconstruction.
- Conducted extensive experiments on Rain200H and VOC2012 datasets using LPNet and DeepLabv3 architectures, showing that our variants outperform baseline models in both PSNR and mIoU metrics.
ViT-GPT2 Image Captioning Model
This project investigates a transformer-based image captioning model by combining Vision Transformer (ViT) and GPT-2, which addresses limitations of traditional CNN-RNN models like Show-and-Tell.
- Extracted visual features using pretrained ViT and generated captions using pretrained GPT-2 with cross-attention.
- Built and trained two versions of the model: ViT(Base) + GPT2(Small) and ViT(Large) + GPT2(Middle), across four datasets (Flickr8k, Flickr30k, COCO150k, COCO250k).
- Outperformed the baseline Show-and-Tell in both BLEU scores and BERT semantic similarity using only 40% of the training data and half the epochs.
Generation of realistic 2D scenes by Text-to-2D Models
Click to view the Research Report
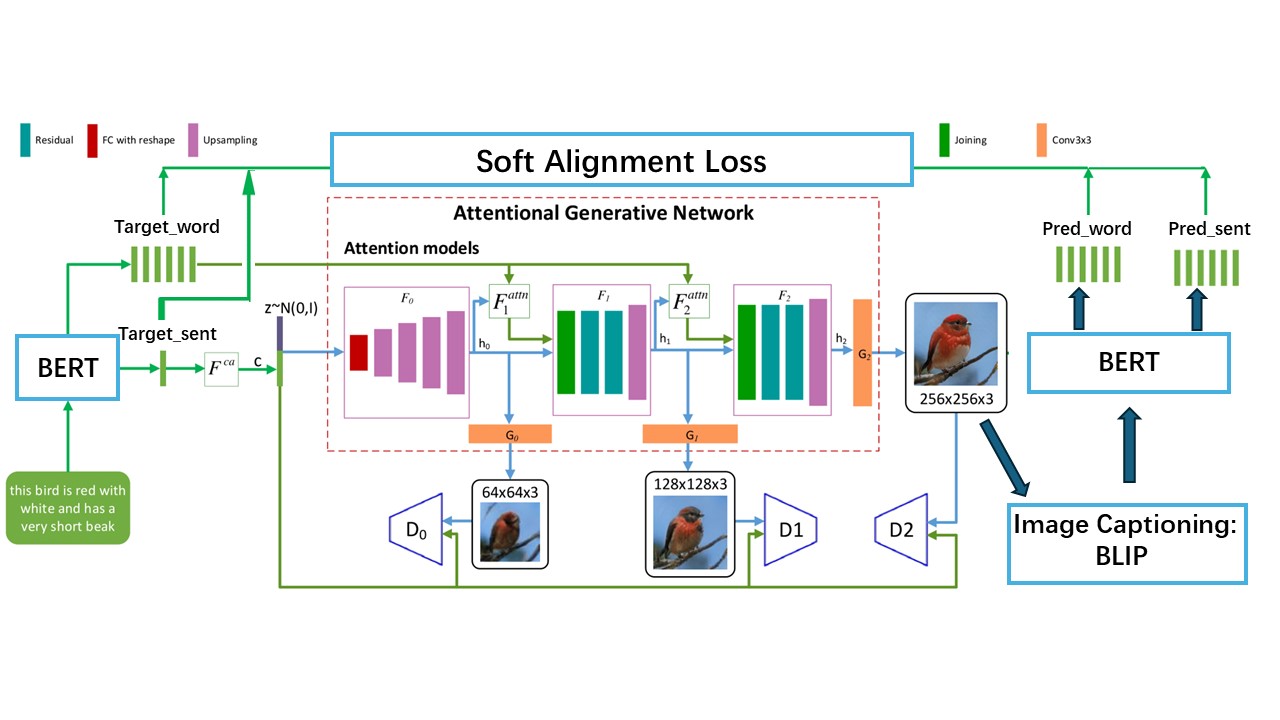
This project aimed to improve a text-to-image model AttnGAN in terms of textual understanding and training efficiency.
- Developed a architecture called Trans_AttnGAN. Employed a pre-trained BERT as the text encoder for generating more contextually accurate sentences and word embeddings.
- Designed a Soft Alignment Loss, leveraging a pre-trained image captioning BLIP followed by a BERT to generate fine-grained guidance in sentence and word level.
- Verified that Trans_AttnGAN achieved comparable performance to AttnGAN with roughly half of the total training time on the CUB-200 dataset.
Music Genre Classifier Paper
Trained and fine-tuned 9 different machine learning models for music genre classification, which are SVM, Logistic Regression, KNN, Naive Bayes, QDA, Random Forest, MLP, CatBoost, XGBoost.
- Group leader
- Use the FMA music dataset containing metadata, features, and genres for over 100,000 tracks.
- Preprocess data by cleaning, word2vec, filling missing values, and normalizing.
- Feature selection with Chi-square and Dimensionality reduction with PCA.
- 5 fold cross-validation to fine tune the 9 models.
- Evaluate the best 9 models on test set using accuracy and macro F1 score.
Movie Review Sentiment Classifier
Build a RNN-based model using Pytorch for sentiment classification on the movie reviews.
- Preprocess the "Large Movie Review Dataset", including tokenization using SpaCy, construction of the one-hot vocabulary.
- Modified architeture: Embedding layer + Bi-directional 2-layer LSTM + Linear layer.
CNNs for Handwritten Digit Classification
The goal of this project was to build and modify two CNN models using Keras and PyTorch to classify handwritten digits.
- Implemented baseline CNN models on MNIST dataset for digit classification
- Tuned model architectures by varying number of layers, kernel sizes, and nodes
ResNet and Gradient Vanishing
This project investigated the gradient vanishing problem and ResNet in Tenserflow and Keras.
- Demonstrated the gradient vanishing issue in a feedforward network with tanh activation and solved the problem using ResNet.
- Identified the maximum layers for ffnet (21 layers) and ResNet (63 layers) with tanh activation before gradient vanishing emerges.
- Showed that switching the activation function to ReLU in ffnet and ResNet further increases their resilience to gradient vanishing (22 layers for ffnet, 81 for ResNet).
Analysis of MLP and CNN in Pattern Recognition
This project analyzed the performance and parameter settings of MLP and CNN on MNIST and CIFAR 10 dataset in Matlab.
- Experimented with various MLP structures and parameters on the MNIST dataset.
- Implemented CNNs on MNIST and CIFAR 10 datasets, adjusting channels and pooling methods.
- Fine-tuned to get the best CNN on MNIST which gained 0.968 and 0.9 for traning and testing accuracy, respectively.
A Model of Residual Sugar Content and Volatile Acidity Content in Wine Using MLE
Apply maximum likelihood estimation to model the relationship between residual sugar content and volatile acidity content in wine in Python.
- Based on the chemical equation: C6H12O6+2O2 = 2CH3COOH + 2CO2 +2H2O, the hypothesis that there is a linear relationship between volatile acidity and residual sugar is made, i.e., residual sugar (y) and volatile acidity (x) can be represented by a linear function y = a + bx, where a and b are coefficients
- According to MLE, mathematically derive the expressions for the parameters a and b.
- Use polyfit function to calculate the coefficients, visualize the results and find out linear relationship is not efficient in describing the relationship between residual sugar and volatile acidity.
- Finally, extend the experiment to quadratic and cubic, compare the performance of the three models and find out the cubic model performs the best.